Relative and absolute paths in Linux
Paths is a topic that causes a lot of confusion for people that want to learn how to make use of the command line in Linux. In this post I will explain what paths are, and the difference between absolute and relative paths. By the end of this post you should be able to understand the diagram below.
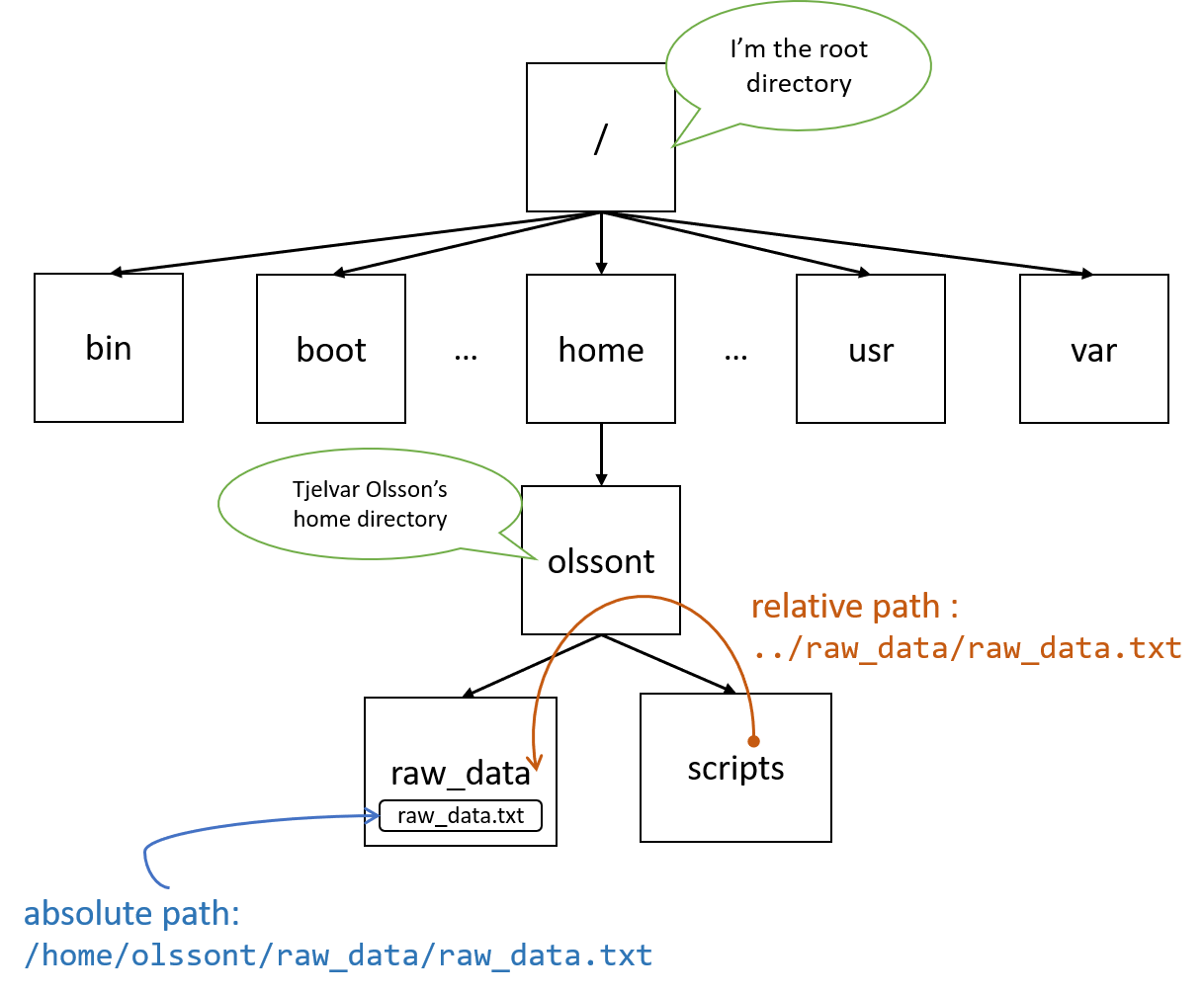
The file system on Unix-like systems is built up like a tree starting from the
root directory (/). One can view the content of the root directory by
typing in the command ls /.
$ ls
bin boot dev etc home lib lib64 media mnt opt proc root
run sbin srv sys tmp usr var
The term “path” refers to the name of a file or directory that can be used to
uniquely identify it in the file system. For example, the command pwd
prints the name of the current working directory, in this case my home directory.
$ pwd
/home/olssont
In the above /home/olssont is the path to the directory that I am currently
in. To illustrate this further we can create a file in this directory. The
command below creates a file named raw_data.txt.
$ echo "Raw data isn't baked data" > raw_data.txt
We can see the files in the working directory using the command ls.
$ ls
raw_data.txt
Depending on how many files you have in your working directory you may see more output from the command above.
To print the content of the file one can use the command cat.
$ cat raw_data.txt
Raw data isn't baked data
In the above the text raw_data.txt could be used to find the file that we
just created. This was because the file was present in the working directory.
So how can we refer to a file if it is not present in the working directory? This is where the use of absolute and relative paths comes into play.
To illustrate this we will use the command mkdir to create a new directory
called raw_data.
$ mkdir raw_data
Then we will use the command mv to move the file into that directory.
$ mv raw_data.txt raw_data/
Before illustrating the correct way to refer to the file let us see what happens if we use the same command as previously.
$ cat raw_data.txt
cat: raw_data.txt: No such file or directory
The cat command is no longer able to find the file (or rather the file is
no longer there, because we moved it into the raw_data directory). There
are two methods that you could use to refer to the file in the raw_data
directory. The first is to use the absolute path, in this case
/home/olssont/raw_data/raw_data.txt. Note that the absolute path to your
file will be different if your username is different to mine and/or if you are
not working in your home directory.
$ cat /home/olssont/raw_data/raw_data.txt
Raw data isn't baked data
The second method is to make use of a relative path, that means a path that
is relative to your current working directory, in this case raw_data/raw_data.txt.
The forward slash (/) is the symbol used to separate directories and files.
$ cat raw_data/raw_data.txt
Raw data isn't baked data
A different way to represent this relative path is to prepend it with ./, where
the dot is a symbol that is used to represent the current working directory. Some
people prefer this way because it makes it easer to see that it is a relative path.
$ cat ./raw_data/raw_data.txt
Raw data isn't baked data
To illustrate the concept of relative paths further we will create another
directory called scripts.
$ mkdir scripts
Now we will change our working directory to be scripts using the cd
(change directory) command.
$ cd scripts
Let us see what happens if we run the previous cat command again (you
should be able to get back to this by using the up and down arrows on your
keyboard to navigate through the command line history).
$ cat ./raw_data/raw_data.txt
cat: ./raw_data/raw_data.txt: No such file or directory
The command above fails because it expects to be able to find a directory named
raw_data in the current working directory and because we have moved into
the scripts directory there is no such directory.
In order to make this work we need to be able to specify that we want to go
up one level in the directory tree. This can be achieved using double dots,
i.e. using the prefix ../. To refer to something two levels up in the
directory tree one would use the prefix ../../, and so forth.
$ cat ../raw_data/raw_data.txt
Raw data isn't baked data
To summarise:
- Paths are used to refer to unique files
- An absolute path starts at the top of the directory tree and includes all
parent directories separated by slashes as well as the file or directory of
interest. Examples of absolute paths include
/home/olssont(a directory),/home/olssont/raw_data/raw_data.txt(a file) - Relative paths are used to refer to files and directories with respect to the current working directory
- In a relative path the prefix
./means the current working directory, the prefix../means the parent directory, and the prefix../../means the parent’s parent directory, and so forth
This should be enough to get you started with paths in the Linux command line. In the next post I will show how relative paths can be used to make scripts more portable, and how they can be used to improve your data management.