Packaging data and metadata using dtool
Introduction
In the previous post I described four principles for effective data management.
- Make it clear who is responsible for what
- Keep raw data safe and separate from derived data
- Standardise the location and structure of data
- Provide metadata
Getting a research group together and discussing these principles can lead to a more coherent strategy for managing data. However, the fourth principle presents a challenge in that currently there is no perfect solution for associating metadata with data.
What is metadata anyway?
Metadata is data about data. Take, for example, an experiment comparing the expression profiles of different tissues in mouse. In this example the species, Mus musculus, is a key piece of metadata that needs to be recorded and associated with the data. Another key piece of metadata to make sense of the data is the tissue. In other words one would need to record the tissue associated each expression profile. These types of metadata are called descriptive metadata. Without these descriptive metadata it would be impossible to draw any conclusions from the data.
When working with digital files one can also think of sizes and checksums of the files themselves as metadata. This type of metadata is called structural metadata. Structural metadata can be useful to ensure that files have not become corrupted. For example, sequencing companies typically provide MD5 checksums alongside the raw data files so that the downloaded sequence files can be verified to contain the expected content.
There is also a third type of metadata called administrative metadata. Administrative metadata is used to manage data as a resource. For example a UniProt identifier is a piece of administrative metadata used manage a protein in the UniProt database.
Although metadata is essential for making sense of data finding solutions for managing metadata can be difficult. In some cases metadata resides inside the heads of individuals. This is not a sustainable solution!
One strategy for associating metadata with files is to include the metadata in directory
structures and file names. This takes the form of file paths along the lines of
replicate_1/chitin/col0_leaf_1.tif. Here the file name tells us that the
image is from leaf sample one from the Colombia-0 ecotype of A. thaliana.
The directory structure encodes that this is replicate one and that the sample
has been treated with chitin.
Using file names and directory structures to store metadata is better than keeping it in ones head. However, it is also fragile in that the metadata can easily be lost if one moves or renames the file.
In this post I will describe our approach to overcoming this problem.
Executive summary
Our solution was to develop dtool, a utility to package metadata with data and treat the two as a unified whole. In dtool terminology the packaged data and metadata is referred to as a dataset.
A dataset can be likened to a box with items in it and a label on it describing its content. The items in the box are the data and the label the metadata.
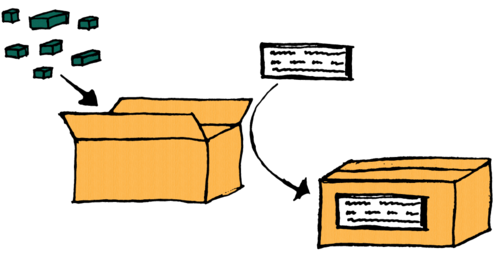
There are several benefits to this approach, some of which only become apparent once one has spent some time using dtool to manage data. However, in brief, dtool prevents accidental loss of metadata when moving data around. It also enables researchers to store and work with data in a variety of storage solutions, and it has built in support for verifying the integrity of a dataset. In other words dtool automates a lot of tedious work associated with data management, and gives researchers peace of mind that their data are safe and secure.
The dtool software was recently published in PeerJ Lightweight data management with dtool.
The hairy details
At its core dtool is a command line utility (with a Python API) that can be used to create and interact with datasets.
First of all one needs to install the software. This can be done using the Python package installer pip.
$ pip install dtool
dtool can be used to retrieve and display the descriptive metadata of a dataset. In the example below the URL refers to a dataset hosted in the cloud.
$ dtool readme show http://bit.ly/Ecoli-ref-genome
description: U00096.3 genome with Bowtie2 indices
organism: Escherichia coli str. K-12 substr. MG1655
accession_id: U00096.3
link: https://www.ebi.ac.uk/ena/data/view/U00096.3
index_builder: bowtie2-build version 2.3.3
index_build_cmd: bowtie2-build U00096.3.fasta reference
From this metadata one can discern that this dataset contains an E. coli reference genome with Bowtie2 indices.
Using dtool it is possible to list the files in the dataset.
$ dtool ls http://bit.ly/Ecoli-ref-genome
dda8452b346d51b9cf60f0662ef3d6e3b6da2e74 reference.2.bt2
d21454a7338c53eabc8d8ed7c2f9c3ff4585c4cf reference.3.bt2
41fb9ae5d4f6c37226ff324c701b84bc3110709e reference.1.bt2
b445ff5a1e468ab48628a00a944cac2e007fb9bc U00096.3.fasta
37e2d68bb38271036d96b6979d24666e0d4fd814 reference.rev.1.bt2
23ebd7cd21a905d5f255919ca1d0491901cb8718 reference.4.bt2
828ebf503926b7c1b8b07c1995b4ca818814b404 reference.rev.2.bt2
The output above lists identifiers and the relative paths of all the files in the dataset. In dtool terminology the files in a dataset are referred to as items.
It is also possible to get administrative and structural metadata from a dataset.
This can be achieved using the dtool summary command.
$ dtool summary http://bit.ly/Ecoli-ref-genome
name: Escherichia-coli-ref-genome
uuid: 8ecd8e05-558a-48e2-b563-0c9ea273e71e
creator_username: olssont
number_of_items: 7
size: 18.8MiB
frozen_at: 2018-09-26
From this one can see, amongst other things, that the data is 18.8MiB in
size and that it has been given the Universally Unique Identifier (UUID)
8ecd8e05-558a-48e2-b563-0c9ea273e71e.
This particular dataset can be useful if one has E. coli RNA sequencing data that one wants to align using Bowtie2. However, in order to make use of the dataset one needs to download it from the cloud to local filesystem. In the example below a directory for storing datasets is created, and dtool is used to download the dataset into this directory.
$ mkdir datasets
$ dtool cp -q http://bit.ly/Ecoli-ref-genome datasets/
file:///Users/olssont/datasets/Escherichia-coli-ref-genome
The command above achieved a lot. It downloaded all the data and metadata from a dataset stored in the cloud, in an Amazon S3 bucket to be precise, and reconstructed the dataset on local disk. Note that this involved working with two different storage technologies, both S3 object storage and filesystem.
All the commands that we have been using on the dataset hosted in the cloud work the same on the dataset stored on local filesystem.
$ dtool readme show datasets/Escherichia-coli-ref-genome
description: U00096.3 genome with Bowtie2 indices
organism: Escherichia coli str. K-12 substr. MG1655
accession_id: U00096.3
link: https://www.ebi.ac.uk/ena/data/view/U00096.3
index_builder: bowtie2-build version 2.3.3
index_build_cmd: bowtie2-build U00096.3.fasta reference
The structure the dataset on the local filesystem is shown below.
$ tree datasets/Escherichia-coli-ref-genome
datasets/Escherichia-coli-ref-genome
├── README.yml
└── data
├── U00096.3.fasta
├── reference.1.bt2
├── reference.2.bt2
├── reference.3.bt2
├── reference.4.bt2
├── reference.rev.1.bt2
└── reference.rev.2.bt2
1 directory, 8 files
From the above we can see that the data files are stored in a subdirectory
named data. The descriptive metadata is stored in the README.yml file.
$ cat datasets/Escherichia-coli-ref-genome/README.yml
description: U00096.3 genome with Bowtie2 indices
organism: Escherichia coli str. K-12 substr. MG1655
accession_id: U00096.3
link: https://www.ebi.ac.uk/ena/data/view/U00096.3
index_builder: bowtie2-build version 2.3.3
index_build_cmd: bowtie2-build U00096.3.fasta reference
On filesystem the data and metadata are stored in files. Furthermore, the metadata files are plain text and make use of open standards. This makes it possible to read and understand them without the need for specialised tools.
In this section three important features of dtool have been highlighted:
-
The dtool command line interface can be used to inspect a dataset’s metadata allowing one to understand the content of the dataset.
-
When copying a dataset with dtool both the data and the metadata are copied across. This means that it is possible to copy datasets, for example to long-term storage systems, without fear of loosing metadata.
-
dtool supports several storage systems including both filesystem and Amazon S3 object storage. This make it possible to copy datasets between different storage systems without having to learn the specifics (and quirks) of the various storage systems.
Creating a dataset
So far the use and benefits of dtool have been illustrated using an existing dataset. Now we will go through the process of creating a dataset.
The creation of a dataset happens in three stages:
- One creates a “proto” dataset that one can add data and metadata to
- One adds the data and metadata to the proto dataset
- One converts the proto dataset into a dataset by “freezing” it
This can be likened to creating an open box (the proto dataset), putting items (data) into it, sticking a label (metadata) on it, and closing the box (freezing the dataset).
Now we will create a minimal dataset containing a single file with the content
Hola Mundo. The command below creates a dataset named hello in
the datasets directory.
$ dtool create hello datasets/
Created proto dataset file:///Users/olssont/datasets/hello
Next steps:
1. Add raw data, eg:
dtool add item my_file.txt file:///Users/olssont/datasets/hello
Or use your system commands, e.g:
mv my_data_directory /Users/olssont/datasets/hello/data/
2. Add descriptive metadata, e.g:
dtool readme interactive file:///Users/olssont/datasets/hello
3. Convert the proto dataset into a dataset:
dtool freeze file:///Users/olssont/datasets/hello
Now we add a file named greeting.txt to the proto dataset.
$ echo "Hola Mundo" > datasets/hello/data/greeting.txt
There are several ways to add descriptive metadata to a dataset. Below we make use of dtool’s built-in template to interactively prompt for metadata to describe the dataset.
$ dtool readme interactive datasets/hello
description [Dataset description]: Hello World greeting in Spanish
project [Project name]: dtool demo
confidential [False]:
personally_identifiable_information [False]:
name [Tjelvar Olsson]:
email [tjelvar.olsson@dtool-solutions.com]:
username [olssont]:
Updated readme
To edit the readme using your default editor:
dtool readme edit file:///Users/olssont/datasets/hello
Finally, we need to convert the proto dataset into a dataset by freezing it.
$ dtool freeze datasets/hello
Generating manifest [####################################] 100% greeting.txt
Dataset frozen file:///Users/olssont/datasets/hello
Congratulations, you have just created your first dtool dataset!
Validating the integrity of a dataset
The dtool freeze command generates a manifest containing structural metadata.
In the manifest each file in the data directory is given an identifier that is
the SHA1 checksum of the file’s relative path in the data directory. The identifiers
are used to create one record for each data item containing the file’s relative path,
size, checksum and timestamp. Below is the content of the manifest file.
$ cat datasets/hello/.dtool/manifest.json
{
"dtoolcore_version": "3.8.0",
"hash_function": "md5sum_hexdigest",
"items": {
"0ce56d0a6e9baa0c5d170001592c9b9c65d19276": {
"hash": "b4b9e397fb7e08bfeaa54090d2989e53",
"relpath": "greeting.txt",
"size_in_bytes": 11,
"utc_timestamp": 1551631241.827989
}
}
}
This information can be used to verify the integrity of the dataset by checking that the expected items are present and that they have the correct size and content.
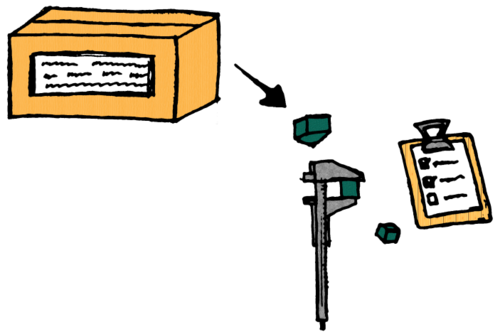
Using dtool this type of integrity check can be performed using the dtool
verify command.
$ dtool verify --full datasets/hello
All good :)
In the command above we use the --full flag to include the step to compute and
compare the checksum. Only item identifiers and sizes are verified by default as
computing checksums can be time consuming for datasets that contain lots of large
files.
We can simulate data corruption by editing the data/greeting.txt file in the dataset.
$ echo "Bonjour le Monde" > datasets/hello/data/greeting.txt
The data/greeting.txt file no longer contains the expected content, it has
been corrupted. Let’s see the output of the dtool verify command.
$ dtool verify --full datasets/hello
Altered item size: 0ce56d0a6e9baa0c5d170001592c9b9c65d19276 greeting.txt
Altered item hash: 0ce56d0a6e9baa0c5d170001592c9b9c65d19276 greeting.txt
In the above the content of the hello/data directory is compared against
the expected content stored in the manifest. In this case both the file size and
checksum of the greeting.txt file are different and this is reported back
to the user.
DISCUSSION
In this post I have shown how one can use dtool to package data and metadata into a unified whole. Using dtool to manage data provides several benefits:
- It prompts people to add metadata to describe their data, making the data more reusable
- It standardises the structure of the metadata, making it easier to access the metadata
- It makes it possible to verify the integrity of dataset, providing peace of mind that data is intact
- It makes it possible to copy a dataset without fear of loosing metadata
- It makes it possible to copy a dataset between different types of storage systems, e.g. from filesystem to Amazon S3 object storage
There are several aspects of dtool this post did not go into. For example, it is possible to customise the template used to prompt for descriptive metadata. This, and other more advanced topics, will be the topics of future blog posts.
If you are keen to find out more about dtool I suggest having a look at the paper Lightweight data management with dtool and the dtool documentation.
If you have made it this far you deserve a lollipop!